


The Spectre/Meltdown pair of vulnerabilities that was published last January shook the entire tech world. These vulnerabilities affected entire ranges of CPUs, including those found in mobile devices, by allowing an attacker to steal data from other programs and potentially execute arbitrary code.
This incident forced cloud service providers to patch their entire fleet of servers. Since the patches are applied at the system level, a reboot was required. On conventional systems, this means downtime. Our Enterprise WordPress hosting architecture , built with high-availability at its foundation, enabled us to patch hundreds of servers against Spectre/Meltdown without experiencing any outage, or service disruption. We decided to show you how we accomplished that, and we invite you to take a deeper look into WordPress High Availability!
High Availability mitigates WordPress downtimes
High Availability architecture leverages a fundamental design principle called component redundancy. With component redundancy, there is at least one extra component, that can be used in case of failure. For example, instead of having only one server, as it might be with cheap VPS setups (we’ll use the term WordPress stack from now on, as it is more accurate), your WordPress site is served by multiple ones. Enterprise WordPress hosting usually includes a highly available setup but in our case, all WordPress plans are highly available!
Having multiple WordPress stacks serving one WordPress site presents a lot of benefits, but most importantly, it allows you to perform maintenance operations without experiencing any downtime at all. This is accomplished by patching each WordPress stack in a ‘rolling restart’ sequence.
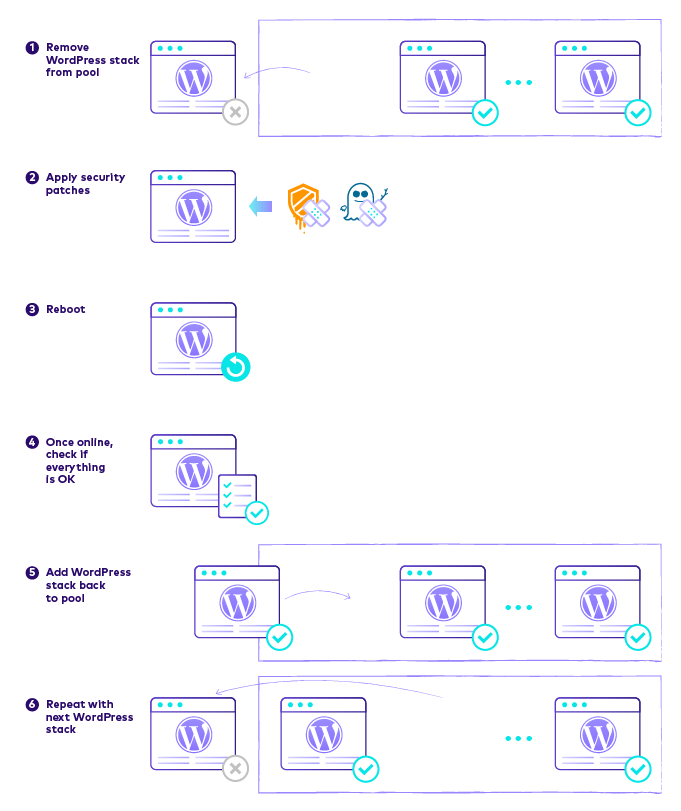
The procedure goes like this: We remove the first WordPress stack from the pool and this makes it stop serving live traffic. Next, we apply the software patches and issue a reboot. While the first stack is being rebooted, the others continue to serve the WordPress site, uninterrupted.
Once it gets back online, we check that the software patches were applied properly and that everything works OK. After the health checks are over, the WordPress stack is added back to the pool. We repeat the whole procedure with the next WordPress stack until all of them are patched.
This way, there is at least one operational WordPress stack that serves the WordPress site, during the maintenance procedure.
High Availability happens “behind the scenes”
All this magic takes place without the user noticing anything out of the ordinary. But there’s a slight paradox at work here! The goal of high availability is to ensure the continuous operation of a system, even in the case of failures, or maintenance operations. However, when a highly-available system does its job properly, it becomes “invisible”. Just like oxygen, it is only noticed when absent.
With this in mind, we have set out to create an introductory presentation on High Availability, geared towards both WordPress developers and more business-oriented people. Specifically, we wanted to accomplish the following:
- Explain how High Availability works in a simple yet conceptually complete way. High availability is an exciting but vast technical subject that you can get easily lost in. This presentation is a guideline to aid you in further research.
- Present a few practical examples of how WordPress behaves in highly-available systems. Specifically, we take a look at plugins, themes, and user sessions.
- Guide you in your decision-making process when choosing a High-Availability hosting provider for your business. There is a lot of information out there that is either vague, buzzword-ridden or just plain wrong.
And as promised, here is the presentation introducing High Availability for WordPress developers:
Start Your 14 Day Free Trial
Try our award winning WordPress Hosting!



















