

The Agency reality nobody talks about
WordPress agencies today spend a surprising amount of time just keeping things from falling apart. Not to make sites dramatically faster or push security to the next level, but simply to keep performance, uptime, and behavior consistent.
Most agencies didn’t set out to become infrastructure operators. But as expectations around speed, security, and availability rose, responsibility began to shift quietly onto the people managing those sites.
Over time, that responsibility expanded to include how plugins interact, how CDNs cache content, and how traffic spikes are handled. None of these systems was designed as a single whole, yet they are now expected to behave like one.
From the outside, clients see only a website. When something slows down, breaks, or behaves unpredictably, the question lands with the agency.
This article examines how WordPress agencies became the connective tissue holding modern infrastructure together, and why the underlying stack model is starting to reach its limits.
The cost of scaling WordPress sites as an agency
Each site adds a little variation. One client insists on a specific host, another depends on a legacy plugin, or a site gets traffic spikes that don’t show up anywhere else.

But every additional configuration or exception each site adds expands the maintenance work, even when nothing is actively “wrong.” Agencies spend more time and energy on keeping performance and security stable than on moving clients forward.

Moreover, agencies mostly rely on tools that are priced per site. So as portfolios grow, those licensing costs rise automatically before any additional value is delivered.
Profit margins eventually tighten, not because agencies underprice their work, but because the work required just to keep things stable keeps increasing.
So the business looks healthy, clients are satisfied, but the operating model quietly demands more attention every month, even before anything goes wrong.
These pressures are the first visible signs of a deeper structural limitation.
The model that collapses as an agency scale
Most WordPress agencies today rely on some variation of the same approach:
- Performance plugins for caching and front-end optimization
- Security plugins for application-level protection
- A CDN service for global delivery
- A hosting, often chosen by the client or inherited from past decisions
- Monitoring tools to detect regressions before clients do.
This approach became the “best practice” WordPress stack for performance and security and did not emerge by accident. At the time, it felt like the right move. Each layer does what it promises and each tool is competent in isolation.
How multiple WordPress sites break the stack
This setup can work fine when an agency is managing just a few sites. The problems start when agencies are responsible for many sites at once, each with its own history, hosting setup, plugin mix, and traffic behavior.
What happens is that over time, fixes stop carrying over. Every plugin update, configuration change, or traffic anomaly introduces new interactions to account for:
🚫 A caching tweak that helps one site will break another
Full-page caching for logged-in users speeds up a content site with simple member access, giving faster TTFB and fewer origin hits.
If, for example, the same rule is reused on a WooCommerce site, users will start seeing other customers’ carts, account pages show stale data and orders fail intermittently.
The “performance win” for one site becomes a data integrity bug on another site.
🚫 A security rule that works on one site causes noise on another
An agency tightens a Web Application Firewall rule to aggressively block XML-RPC requests and repeated POSTs to /wp-login.php. On a simple brochure site, it works fine against brute-force noise and security improves with no visible side effects.
Then the same rule is reused on a site with a form plugin that retries POST requests. Suddenly, legitimate users receive 403 errors, form submissions become unreliable and support tickets roll in with complaints.
Responsibility is fragmented across tools
When using this stack of tools, no single layer sees the whole picture. Hosting owns the origin. The CDN owns delivery. Plugins own application rules. Agencies own the blame.

So when performance degrades or an attack hits, no single system has end-to-end visibility. At scale, this turns agencies into incident coordinators without a unified control plane.
Eventually, the flexibility that made this model attractive now makes it fragile. What began as modularity gradually turned into coordination.
If you run an agency, you know that this is the point where scale starts working against you.
The backlash response
In a situation like this, the instinctive response is almost always the same. To tighten standards.
To document clearer rules, introduce better processes, add one more tool to close whatever gap just appeared.
This response makes sense. Agencies are disciplined operators. When something feels unstable, their natural assumption is that it can be stabilized through better configuration and tighter control.
But in reality, even well-tuned WordPress stacks degrade naturally as sites evolve.
Such WordPress environments are assembled from multiple independent systems, each evolving on its own timeline. WordPress dynamic nature amplifies this drift, but it is the fragmentation between layers that causes it to compound.

At a certain scale, it becomes clear that more coordination cannot turn a fragmented system into a unified one.
When a model reaches its limits
Again, none of this means WordPress is broken or that agencies are doing something wrong.
The stack model worked for a long time. It made sense when sites were simpler, expectations were lower, and scale could be managed through experience and effort.
The real problem is that the model assumes stability can be assembled site by site and preserved through constant coordination. And that is the limit agencies are running into.
Eventually, what matters after a certain point is where responsibility lives.
How we solved the problem
Across agency portfolios, the same pattern appears: as scale increases, coordination expands, and stability demands constant attention.
What we did in Pressidium was step back and ask a more fundamental question: Why should stability need to be managed at all?
When you strip the situation down to first principles, a few things remain true regardless of stack or scale:
🌍 Distance introduces latency.
⚙️Complexity multiplies failure points.
🛡️Security applied late is always reactive.
From those constraints, the answer wasn’t another plugin or service layer. It was architectural.
The problem wasn’t that WordPress or origin infrastructure was failing, but that they were being asked to handle first-response concerns after requests had already reached the most variable and fragile part of the system.
Performance, security, and traffic handling had to move earlier, before WordPress executes and per-site exceptions accumulate. They had to live in a place where they could apply consistently, across every site, by default.
That’s how Pressidium EDGE came to exist. A unified Edge layer we built to move all the responsibility out of individual WordPress sites.
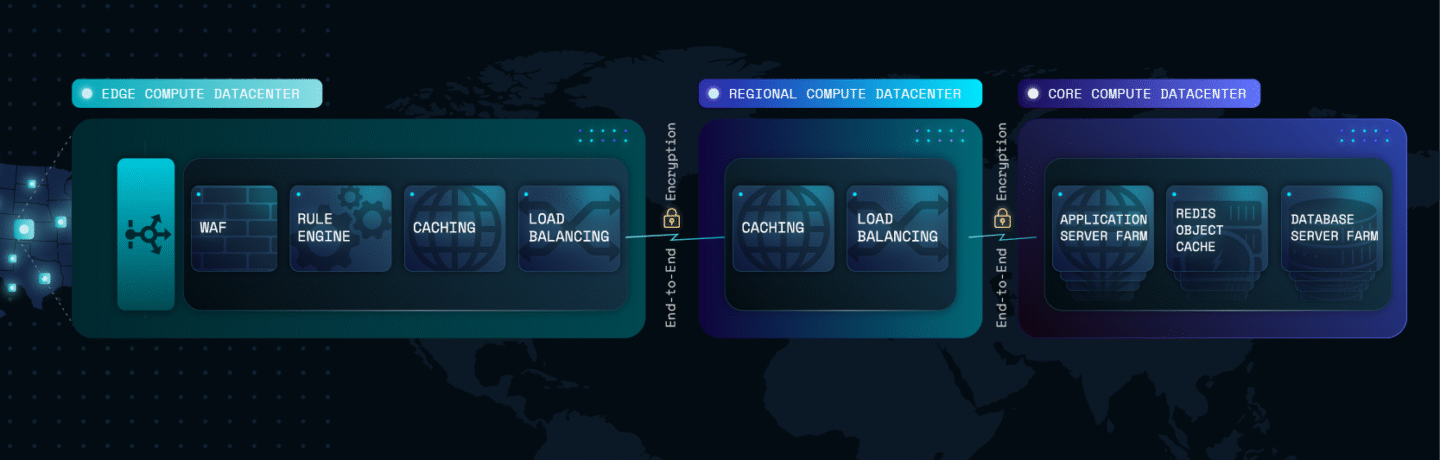
EDGE already operates as the first touchpoint for every request in the Pressidium platform, before traffic reaches WordPress or origin infrastructure.
Why this works in practice
Here’s what that shift looks like in real-world operation.
Pressidium EDGE serves both static and dynamic pages at the edge locations when possible, reducing the number of requests that must be processed by the origin server. That translates directly into faster pages, less ongoing tuning, and fewer long-term stability issues for agencies to manage.

Security is handled the same way. Malicious traffic, bots, and attack patterns are stopped before they reach plugins, login pages, or the database. Agencies don’t have to chase false positives, adjust rules per site, or explain intermittent blocks to clients. Protection happens upstream, consistently, by default.

Traffic spikes are absorbed early as well. Instead of each site reacting differently under load, the Edge layer smooths traffic before it reaches the hosting infrastructure. Sites stay responsive during campaigns, launches, and unexpected spikes without agencies having to prepare special rules in advance.
Because all of this happens before WordPress runs, it behaves the same way across every site in a portfolio. Stability no longer depends on remembering which plugin, exception, or workaround applies where.
WordPress is left to do what it’s good at, serving the application, while performance and protection become structural properties of the platform, not ongoing coordination tasks.
This is the model that has powered the Pressidium platform since 2025, happily supporting real agency portfolios with dynamic sites, logged-in users, and high-traffic events.
Extending Pressidium EDGE
Until now, EDGE has been tightly coupled to our managed WordPress hosting platform, where it operates as part of a single, integrated system.
That is now changing.
We’re making Pressidium EDGE available as a standalone service. An additional delivery option for agencies that want the benefits of our Edge technology without changing their existing hosting setups.
This is a new delivery model and we’re introducing it gradually.
➥ See EDGE Only in action
You can use the EDGE Mirroring Demo to observe how a WordPress site responds when requests are handled at the edge perimeter.

The demo creates a read-only mirror of a page and serves it through the Edge layer, allowing you to examine response timing, caching behavior, and delivery paths without affecting production traffic or migrating infrastructure.
➥ Get early access to EDGE Only
Before broader release, we are opening a limited early access phase to those who want to evaluate Pressidium EDGE without changing their host.
Early access participants receive:
- Free usage during the early access period, regardless of traffic volume
- Exclusive benefits after launch
If you are an agency and want to see for yourself how stability behaves when it becomes structural, click below to join our list.













