

Have you ever wondered what robots.txt file is and what it does? Robots.txt is used to communicate with the web crawlers (known as bots) used by Google and other search engines. It tells them which parts of your website to index and which to ignore. As such the robots.txt file can help make (or potentially break!) your SEO efforts. If you want your website to rank well then a good understanding of robots.txt is essential!
Where Is Robots.txt Located?
WordPress typically runs a so-called ‘virtual’ robots.txt file which means that it is not accessible via SFTP. You can however view its basic contents by going to yourdomain.com/robots.txt. You will probably see something like this:
User-agent: *
Disallow: /wp-admin/
Allow: /wp-admin/admin-ajax.phpThe first line specifies at which bots the rules will apply to. In our example, the asterisk means that it the rules will be applied to all bots (e.g. ones from Google, Bing and so on).
The second line defines a rule that prevents access by bots to the /wp-admin folder and the third line states that bots are allowed to parse the /wp-admin/admin-ajax.php file.
Add Your Own Rules
For a simple WordPress website, the default rules applied by WordPress to the robots.txt file may be more than adequate. If however you want more control and the ability to add your own rules in order to give more specific instruction to search engine bots on how to index your website then you will need to create your own physical robots.txt file and put it under the root directory of your installation.
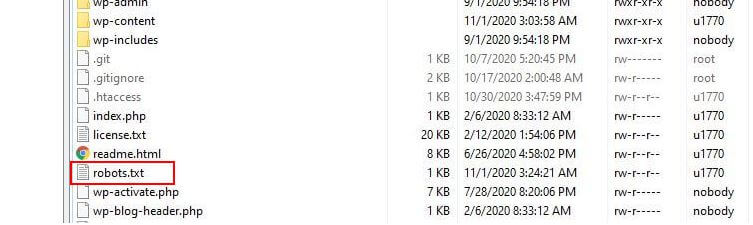
There are several reason that may want to re-configure your robots.txt file and define what exactly those bots will be allowed to crawl. One of the key reasons is to do with the time spent by a bot crawling your site. Google (and others) don’t allow bots to spend unlimited time on every website… with trillions of pages they have to take a more nuanced approach to what their bots will crawl and what they will ignore in an attempt to extract the most useful information about a website.
Try our Award-Winning WordPress Hosting today!

When you allow bots to crawl all pages on your website, a portion of the crawling time is spent on pages that are not important or even relevant. This leaves them with less time to work their way through the more relevant areas of your site. By disallowing bot access to some parts of your website, you increase the time available for bots to extract information from the most relevant parts of your site (which will hopefully end up indexed). Because the crawling is faster, Google is more likely to revisit your website and keep their index of your site up-to-date. This means new blog posts and other fresh content is likely to get indexed faster which is good news.
Examples of Editing Robots.txt
The robots.txt offers plenty of room for customization. As such we’ve provided a range of examples of rules that can be used to dictate how bots index your site.
Allowing or Disallowing Bots
First, let’s look at how we can restrict a specific bot. To do this all we need to do is replace the asterisk (*) with the name of the bot user-agent that we want to block, for example ‘MSNBot’. A comprehensive list of known user-agents is available here.
User-agent: MSNBot
Disallow: /Putting a dash in the second line will restrict the bot’s access to all directories.
To allow only a single bot to crawl our site we’d use a 2 step process. First we’d set this one bot as an exception and then disallow all bots like this:
User-agent: Google
Disallow:
User-agent: *
Disallow: /To allow access to all bots on all content we add these two lines:
User-agent: *
Disallow:The same effect would be achieved by simply creating a robots.txt file and then just leaving it empty.
Blocking Access to Specific Files
Want to stop bots indexing certain files on your website? That’s easy! In the example below we have prevented search engines from accessing all the .pdf files on our website.
User-agent: *
Disallow: /*.pdf$The “$” symbol is used to define the end of the URL. Since this is case sensitive, a file with name my.PDF will still be crawled (note the CAPS).
Complex Logical Expressions
Some search engines, like Google, understand the use of more complicated regular expressions. It’s important to note however that not all search engines might be able to understand logical expressions in robots.txt.
One example of this is using the $ symbol. In robots.txt files this symbol indicates the end of a url. So, in the following example we have blocked search bots from reading and indexing files that end with .php
Disallow: /*.php$This means /index.php can’t be indexed, but /index.php?p=1 could be. This is only useful in very specific circumstances and needs to be used with caution or you run the risk of blocking bot access to files you didn’t mean to!
You can also set different rules for each bot by specifying the rules that apply to them individually. The example code below will restrict access to the wp-admin folder for all bots whilst at the same time blocking access to the entire site for the Bing search engine. You wouldn’t necessarily want to do this but it’s a useful demonstration of how flexible the rules in a robots.txt file can be.
User-agent: *
Disallow: /wp-admin/
User-agent: Bingbot
Disallow: /XML Sitemaps
XML sitemaps really help search bots understand the layout of your website. But in order to be useful, the bot needs to know where the sitemap is located. The ‘sitemap directive’ is used to specifically tell search engines that a) a sitemap of your site exists and b) where they can find it.
Sitemap: http://www.example.com/sitemap.xml
User-agent: *
Disallow:You can also specify multiple sitemap locations:
Sitemap: http://www.example.com/sitemap_1.xml
Sitemap: http://www.example.com/sitemap_2.xml
User-agent:*
DisallowBot Crawl Delays
Another function that can be achieved through the robots.txt file is to tell bots to ‘slow down’ their crawl of your site. This might be necessary if you’re finding that your server is overloaded by high bot traffic levels. To do this, you’d specify the user-agent you want to slow down and then add in a delay.
User-agent: BingBot
Disallow: /wp-admin/
Crawl-delay: 10The number quotes (10) in this is example is the delay you want to occur between crawling individual pages on your site. So, in the example above we’ve asked the Bing Bot to pause for ten seconds between each page it crawls and in doing so giving our server a bit of breathing space.
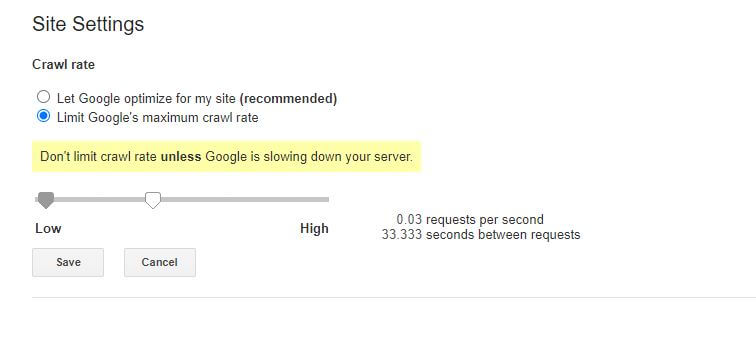
The only slightly bad news about this particular robots.txt rule is that Google’s bot doesn’t respect it. You can however instruct their bots to slow down from within the Google Search Console.
Notes on robots.txt rules:
- All robots.txt rules are case sensitive. Type carefully!
- Make sure that no spaces exist before the command at the start of the line.
- Changes made in robots.txt can take 24-36 hours to be noted by bots.
How to Test and Submit Your WordPress robots.txt File
When you have created a new robots.txt file it’s worth checking there are no errors in it. You can do this by using the Google Search Console.
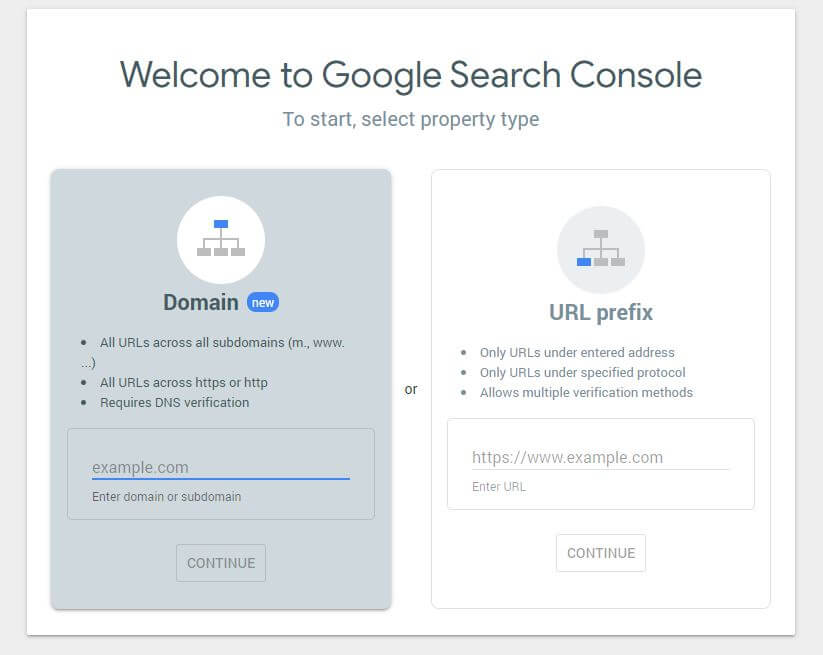
First, you will have to submit your domain (if you haven’t already got a Search Console account for your website setup). Google will provide you with a TXT record which needs to be added to your DNS in order to verify your domain.
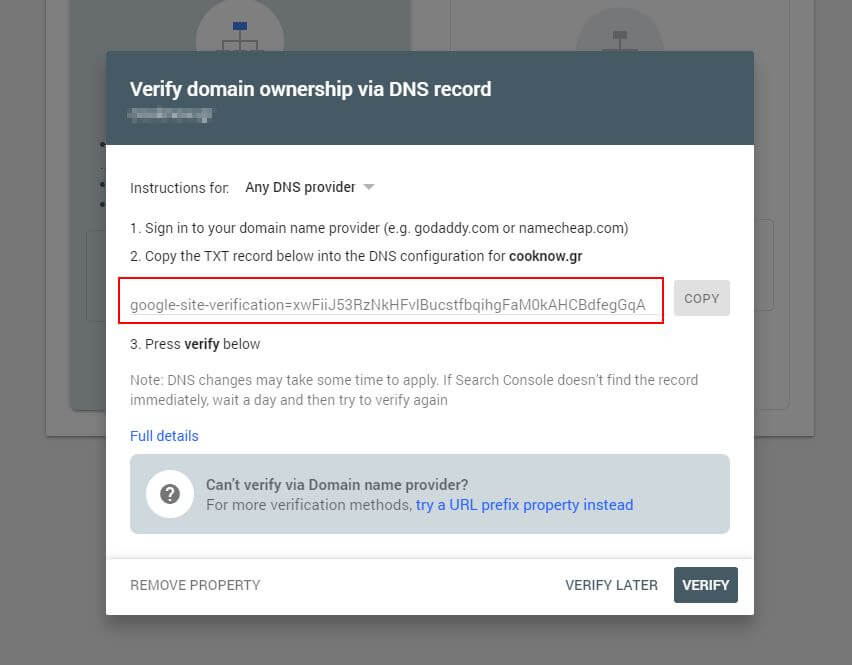
Once this DNS update has propagated (feeling impatient… try using Cloudflare to manage your DNS) you can visit the robots.txt tester and check whether there are any warnings about the contents of your robots.txt file.
Another thing you can do to test the rules you have in place are having the desired effect is to use a robots.txt test tool like Ryte.
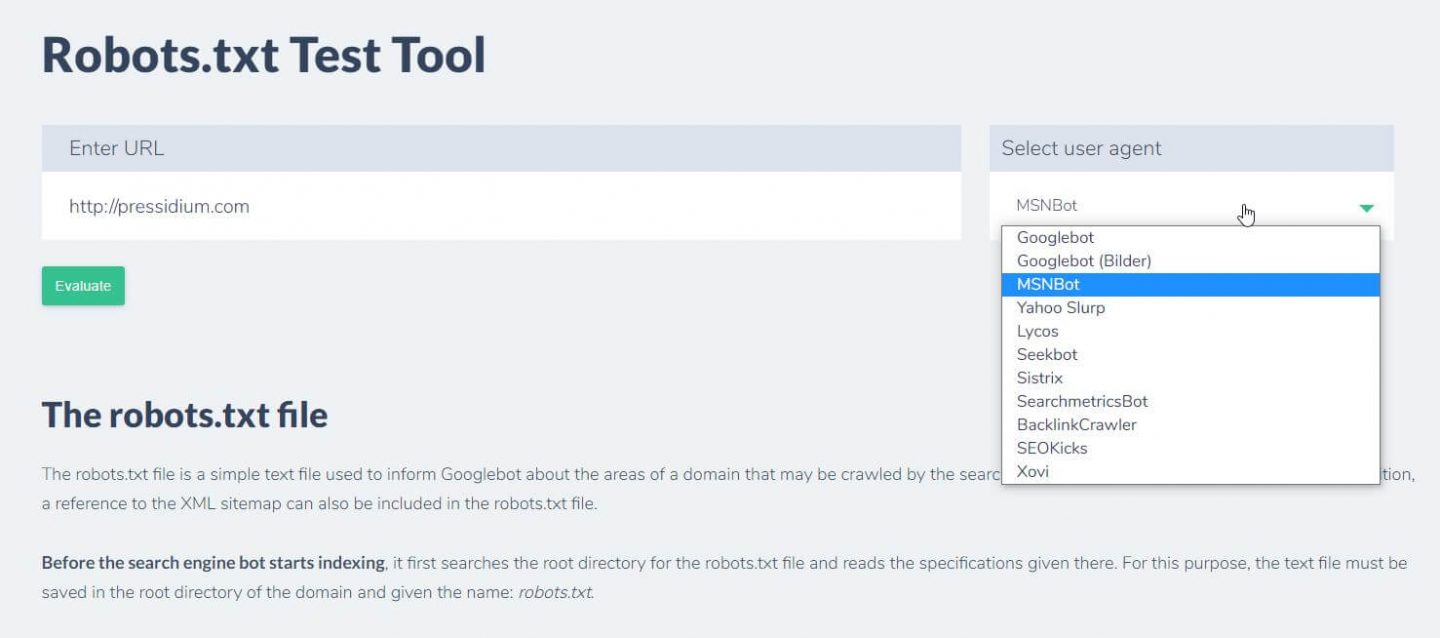
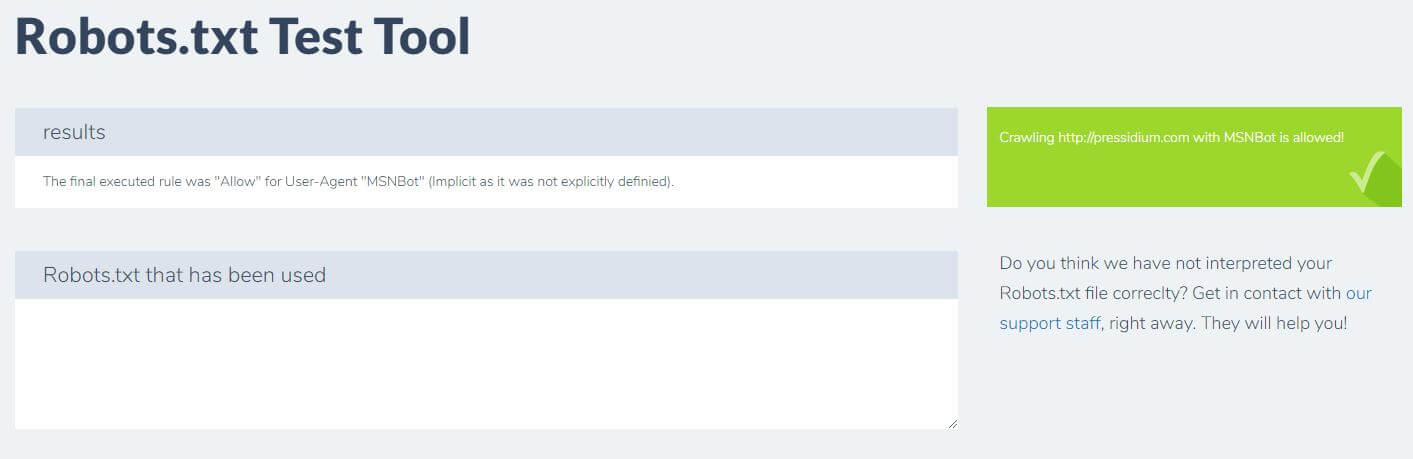
You just enter your domain and choose a user agent from the panel on the right. After submitting this you’ll see your results.
Conclusion
Knowing how to use robots.txt is another useful tool in your Developer’s toolkit. If the only thing you take away from this tutorial is the ability to check that your robots.txt file isn’t blocking bots like Google (which you’d be very unlikely to want to do) then that’s no bad thing! Equally, as you can see, robots.txt offers a whole host of further fine grained control over your website which may one day come in useful.
Start Your 14 Day Free Trial
Try our award winning WordPress Hosting!



















