Content or web scraping, also known as web scraping, is the process where bots copy content from a website. It is possible to even iterate through all the data trees of your website to copy the entire content.
Web scraping though is not bad by design. When search engines are indexing websites, for example, in order to rank them, we have a useful and legitimate implementation of web scraping.
Generally speaking, scraping can be performed without harming the site if it is done slowly. However this is not always the case and can lead to bandwidth consumption that slows down the website.
So the real issue here is the nature of scraping. If we can somehow tell good from bad scrapers, we can keep our website safer.
How to Identify The Problem
Fortunately, there are several ways to distinguish between the good and bad scrapers.
Google Search
Let’s start by ruling out the obvious and taking a manual look online to see if we can spot our content where it shouldn’t be. To do this, just search for your article and page titles in Google. If you only see your website appear with these then that’s all good. Just keep a look out for other websites that come up in the search with content that looks just like yours.
Free Online Tools
There are also great online and free-to-use plagiarism checkers that can help you identify scrapers. A popular one is Copyscape. It is easy to use and provides great features.
With the free version of Copyscape, you can search for your article’s URL to see if there are duplicates. You might get false positives that need to be checked manually, but if there is a copy, you won’t miss it.
Access Logs
You may notice that your site is running slowly for no apparent reason. this could be as a direct result of bad content scrapers occupying significant chunks of your website’s bandwidth.
Try our Award-Winning WordPress Hosting today!

In this instance, your website’s access logs can provide clues as to what is going on. These are normally made available by your host. Ask for a copy and take a look. You should see a list of IP’s that have been visiting your site. This information should be enough to ascertain whether or not your site is being targeted by a bandwidth hungry bot and if so you can take steps to stop it. Read on to find out how!
How to Stop and Prevent Content Scraping
With the problem identified, it’s now time to take steps to stop and prevent content scraping. Here are some of the measures you can take.
Rate Limiting
Rate limiting, or requests throttling, is a technique used to control the rate of sent or received requests. One of its most common uses is limiting web scraping.
When used to prevent bad scrapers, what is accomplished with rate limiting is that you set a maximum number of client-to-server requests, in a certain time, for all or specific IPs. If this limit is exceeded, any request after will be ignored.
Block IPs
You may want to block some IPs in case you have discovered in your access logs that they send too many requests.
You can accomplish this by editing your htaccess file and inserting this line:
Deny from 94.66.58.135Replace the IP in the code with the one you want to block so you will no longer receive requests from it.
Prevent Hotlinking
As we have well described in our article on the .htaccess file, this is a configuration file that can be used in multiple ways to control access to your website.
One of the great benefits of this file is that you can use it to prevent Image Hotlinking. So in cases where your website is scraped, the image links will not redirect back to you and consume unwanted bandwidth, but will display a broken thumbnail and a 403 Forbidden message instead.
To do this open your .htaccess file with your favorite text editor and insert the following code:
RewriteEngine on
RewriteCond %{HTTP_REFERER} !^$
RewriteCond %{HTTP_REFERER} !^http(s)?://(www.)?mycompanyname.com [NC]
RewriteCond %{HTTP_REFERER} !^http(s)?://(www.)?google.com [NC]
RewriteCond %{HTTP_REFERER} !^http(s)?://(www.)?yahoo.com [NC]
RewriteRule .(jpg|jpeg|png|gif)$ - [F]Replace ‘mycompanyname.com’ with the URL of your website.
What we did here is block all websites from hotlinking images on your site with the exception of search engines which we do want to allow to scrape our website.
Use a CAPTCHA
If you are suspicious that your website is being scraped by unwanted bots, you can always use CAPTCHA.
As you may already know, a CAPTCHA is a technique that provides some simple tests for you to solve and approve your are human and not a bot. As such it can be also helpful in preventing web scrapers. Proceed with care however as CAPTCHAs can prove irritating for your real users and result in them visiting your website less.
RSS Feeds
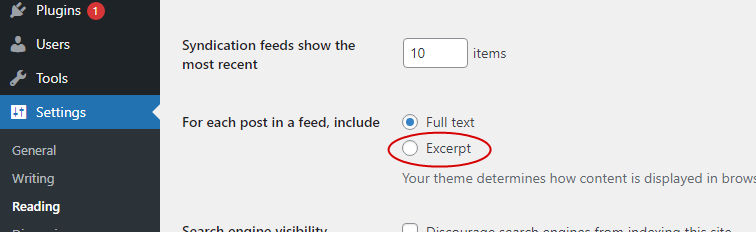
A great way to reduce malicious scraping is by providing a summary RSS feed instead of full RSS feed. This is one more popular way of preventing web scraping. Especially if you are using WordPress, it is very easy to set this option under the Settings -> Reading of the admin menu options.
Do Nothing
There is always the choice of just ignoring the problem, which may sound silly, but in some cases may be a rational decision. If your site is relatively low traffic then you might not want to worry about implementing any of the above measures. If however your site is high traffic and content scraping is having a negative impact on your site (such as slowing it down or affecting your SEO rankings) then definitely take steps to stop it.
Conclusion
Experiencing bad bot content scraping of your site can be frustrating. However you choose to deal with content scraping, the number one priority should be to do so in a way that doesn’t affect the user experience.
Start Your 14 Day Free Trial
Try our award winning WordPress Hosting!